
A recent academic paper was published a few days ago which purports to discredit all conspiracy theories – using bad mathematics to prove its point.
The paper, “On the Viability of Conspiratorial Beliefs,” suggests that many popular conspiracy theories would require an extraordinary number of people to be hiding something in order for them to be true. For instance, if you believe climate change to be fraudulent, the paper’s author suggests that tens of thousands of climate change researchers and scientists would need to be actively covering it up.
The paper also suggests that if the NASA moon landings were faked, over 400,000 NASA employees would have to be in on the scam.
![]()
BYPASS THE CENSORS
Sign up to get unfiltered news delivered straight to your inbox.
You can unsubscribe any time. By subscribing you agree to our Terms of Use
Littleatoms.com reports:
Given those kinds of numbers, it seems almost inevitable that leaks would occur. Can we predict how long a conspiracy of a given size will last? That’s the question asked by Dr David Grimes – the researcher, skeptic and writer who published the paper. If we can prove mathematically that a conspiracy involving 400,000 people can’t last more than a few months or years, then we can easily dismiss a number of popular beliefs.
It’s a nice idea. Unfortunately the answer is a resounding “no”, and the resulting paper ends up being a sort of case study in how not to do statistics. Inevitably media outlets loved it, and so now news feeds are full of headlines like: “Most conspiracy theories are mathematically impossible,” “The maths equation threatening to disprove conspiracy theories”, “Maths study shows conspiracies ‘prone to unraveling’” and so on and on.
Do you want to know a secret?
Let’s imagine we want to predict how long a conspiracy will last. One approach would be to collect a number of examples of existing theories of different sizes and durations, and plot them on a chart. It might look something like the following graph, though ideally with a lot more data points. If we’re really lucky, we might even see a pattern.
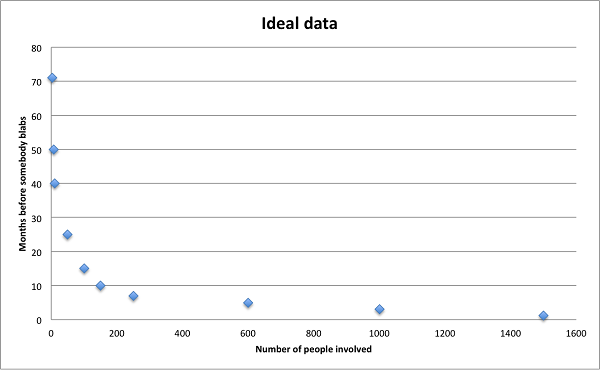
Grimes takes a different approach, except he has a grand total of, well, three examples to extrapolate from. It’s not exactly a data goldmine.
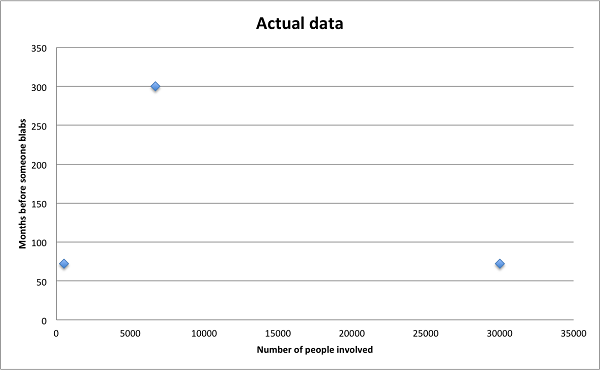
The examples are three real life conspiracies that were eventually exposed – the NSA’s PRISM programme, the Tuskegee syphilis experiment, and a scandal at the FBI about the accuracy of their forensics tests. In each case the number of people involved is complete guesswork. For the NSA Grimes uses a figure of 30,000, which assumes the entire workforce from director down to janitor were involved in one project. In reality it could have been hundreds or even just tens of people. The data is basically nonsense – you could put the points almost anywhere to make whatever pattern you liked.

So there aren’t enough examples, and the few listed aren’t very reliable. They’re also the wrong kind. We’re missing any data on conspiracies that have remained secret for obvious reasons. Two of the three predate the Internet era, and you’d expect a revolutionary global communications system to have some impact on communications. There aren’t any small conspiracies of say 10 or 20 people. All of the examples are big, institutional or community affairs. All three are based in the United States, two in law enforcement or security services where secrecy is part of the job description and the cost of breaking it is extreme.
From these examples, Grimes calculates that the likelihood of a typical person blabbing about their secret conspiracy in a given year is roughly five ten thousandths of a percent. If this were true, there wouldn’t be a word for ‘gossip’ in the dictionary. We’d walk around in stony silence all day tapping our noses at people. The standard response to “How are you?” would be “Never you mind.” It’s the sort of number you accept without thinking when you’ve forgotten that the numbers you’re playing with relate to actual human beings.
Do you promise not to tell?
We could get deeper into the basic premises of the paper. How do you even define a conspiracy, and how is it different to a secret? What does it mean for a conspiracy to leak, and can people even agree on whether a leak has occurred? After all, climate skeptics would point to the University of East Anglia e-mail leak as an example of a leak occurring and large numbers of people becoming aware of ‘the truth’.
For that matter, why should dying prevent someone being the source of a leak (history is littered with examples of lost papers found in attics), and why would his or her probability of leaking remain constant over time, when some conspiracies by their nature are less important to conceal years after the fact?
As it happens though, all that’s irrelevant because there’s a much bigger issue. As far as I can tell the maths underpinning his model is wrong. Several statisticians who I spoke to or who checked the paper independently agree.
The root of the problem lies in this graph. Forget the jargon for a moment. All this shows is the cumulative probability over time of a conspiracy being discovered.
The assumption is that the average person has a 0.0005% chance of leaking in any given year. The blue line shows how the probability grows year after year if 5000 people are involved, all those individual chances adding up with time. This is exactly the same type of curve you’d get if you plotted the odds of rolling a six from a growing number of dice – your odds get closer and closer to 1 but never quite reach it.
The other lines show what happens if you assume that people die off, using two different rates. The orange line assumes half of the people involved die every 10 years, so after a decade there are 2500 people left, 1250 after two decades and so on. The pink line uses a more sophisticated equation for mortality.
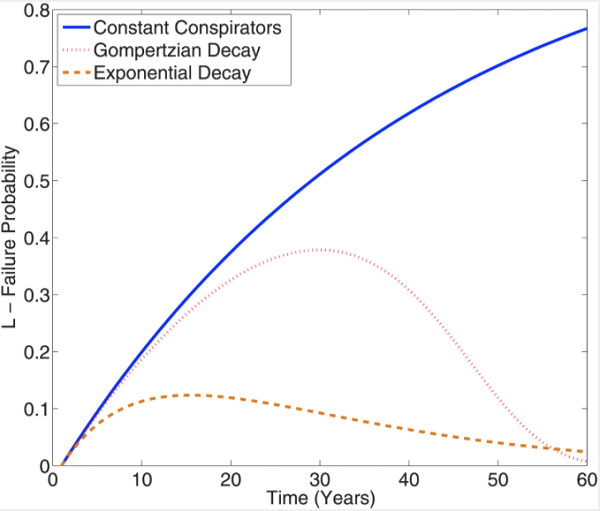
Got that? If so, you’re doing better than the author. Here’s the problem: if the probability of exposure is accumulating over time then why does it start going down? You can’t make a conspiracy secret again! The increase each year should fall toward 0 as the population dies off, leaving the plots to trail off as flat lines.
In fact they don’t account for a changing population at all, as I discovered when I wrote a simple computer simulation to test his model. Thanks to a very basic calculus error, the lines actually show what the cumulative probability would have been if the population had started at the current level and stayed constant. So if we take the orange line at 10 years, instead of telling us the cumulative probability if the population had started at 5000 and fallen to 2500 over time, it gives us the value if the population had started at 2500 and stayed constant. Since this error occurs in equation 1, which the rest of Grimes’s equations are derived from… well, you get the idea.
In truth it doesn’t affect the conclusions too much, because the timelines for the conspiracies Grimes looked at were so short that mortality didn’t really kick in. The conclusion still makes sense – if you have a lot of people, hiding a conspiracy becomes incredibly unlikely. But we knew this already. Even if we corrected his mistake, the model Grimes presents would just be a standard probability curve with some improbable assumptions plugged into it. It doesn’t get us any closer to a prediction for the longevity of any real world conspiracy. As equations go, it’s up there with the infamous Blue Monday – a plausible sounding story for the press that lacks any scientific rigour.
It would be easy to blame Grimes for all this, but the bigger failure here is in PLOS ONE’s peer review process. It’s easy to screw up calculus. What’s less excusable is that expert reviewers looked at this paper ahead of publication, and none of them spotted an elementary mistake that myself and others saw almost immediately. Numerous other helpers are cited in the acknowledgements, but none of them seem to have glanced at the math or challenged some really odd assumptions. Grimes made a mistake – we all do – but he was also severely let down by his peers and colleagues.
And it’s frustrating. It’s frustrating because skeptics and rationalists ended up retweeting news stories that were just as bogus as the bad science they claim to stand against. It’s frustrating because a paper that lashes out against the idea that scientists might be engaged in covering up bad research turns out to be an example of bad research that slipped through peer review. It’s frustrating because the model was so ill thought that Anne Atkins on Radio 4’s Thought for the Day was able to use it as evidence for the resurrection of Christ – after all, if so many people bore witness to it then the maths “proves” that a conspiracy to conceal the truth could not have lasted two millennia.
Which leaves perhaps the biggest question of all: was this really just a bad paper, or was there some deeper purpose behind it? Is Doctor Grimes engaged in some kind of charade, running interference on behalf of a master or masters unknown? Is he still the real Grimes, or has he been replaced by a foppish-haired lizard impersonator? The truth is out there…

Sean Adl-Tabatabai
Be the first to comment